Index building
In Information Retrieval community, it is assumed that discriminating word
senses in requests and documents significantly improves the performance
of information retrieval systems. Some experiments were lead (Gonzalo
et
al., 1998) on documents and requests semantically hand-annotated: the
precision was greatly enhanced. We saw in section 3 that manual annotation
of web pages with ontology is a titanic task. Therefore, we propose a semi-automatic
indexer of web pages. The major problem is to semi-automatically determine
the specific content of documents. The natural language processing community
commonly admitted that terms involved in text, carry relevant information
on text content. Several works (Bourigault, 1994; Daille, 1994) underline
that terms pattern and frequency are determinant to extract terms from
large corpora from a single domain. Unfortunately, web pages are often
small and web sites often cover multiple domains. However, web pages are
structured according to HTML markers, which can be used for weighting terms
importance in pages and then can be exploited for characterizing web page
content.
4.1 Terms extraction
The term extraction begins by (1) removing HTML marker from web pages,
(2) dividing the text in independent sentences, (3) lemmatizing words
included in the page. Next, web pages are annotated (figure 1) with part
of speech tags using the Brill tagger (Brill, 1995). As a result, each
word in a page is annotated with its corresponding grammatical category
(noun, modifier...).
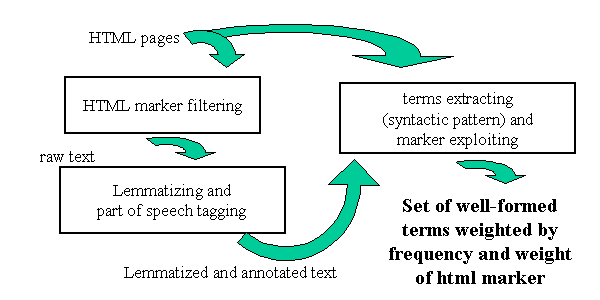
Figure 1. Terms extraction
Finally, the surface structure of sentences is then analysed using term
patterns to provide well-formed terms. To each well-formed term is assigned
a coefficient C according to the term frequency and the weight of
HTML Markers. This last coefficient is called the weighted frequency.
Table 1 shows some results extracted from an experiment on the web site
http://www.cs.washington.edu/.
This web page is the homepage of the departement of computer science of
the University of Washington. A coefficient equal to 1.0 means the term
(here "Washington") is the most relevant index. Other term coefficients
are calculated according to this one. We have extracted well-formed terms
like single term ("science"...) and complex term ("university washington"...).
Note that the term "university washington" provides another term "university
of washington". We provide several forms for a term to improve the term
retrieval process in the thesaurus.
|
Weighted coefficient
|
Terms
|
|
1.00
|
washington
|
|
0.83
|
science
|
|
0.67
|
university washington
|
|
0.67
|
university of washington
|
|
0.67
|
university
|
|
0.67
|
engineering
|
|
0.50
|
program
|
|
0.50
|
computer science
|
|
0.50
|
computer
|
|
0.50
|
college
|
|
0.33
|
uw
|
|
0.33
|
student
|
|
0.33
|
seattle
|
|
0.33
|
member
|
|
0.33
|
major
|
|
0.33
|
field
|
|
...
|
...
|
Table 1. Terms extracted from a web page
4.2. Page concept determination
During the term extracting process, well-formed terms and their coefficient
were respectively extracted and calculated. The well-formed terms are forms
representing a particular concept. Different forms may represent a same
concept (i.e. chair, professorship). In order to determine not only the
term set included in a page but also the concept set included in a page,
linguistic ontologies are used. A linguistic ontology can be viewed as
a machine readable dictionary structured around groups of synonymous words,
which represent a concept. Moreover, it provides explicit relationships
among group of synonymous (i.e. hypernym relationship, meronym relationship...).
Linguistic ontology allows the mapping of concepts and words or terms.
Therefor, in our context, linguistic ontology is used to generate all concepts
corresponding to well-formed term. In our experiment, we have still used
the WordNet linguistic ontology (Miller, 1990).
The process to generate candidate synsets is quite simple: from all
extracted terms, all candidate concepts (all senses) are generated using
WordNet. This thesaurus is a broad coverage linguistic ontology but it
does not cover all the terms included in web page. If a term does not exist
in WordNet, a specific sense is generated. Then, a convenience coefficient
is calculated using a semantic similarity measure (Figure 2). It measures
for a given term (a form), the convenience with all possible concepts it
could represent. The calculus takes terms context into account (the page
in which it appears and its neighbourhood).
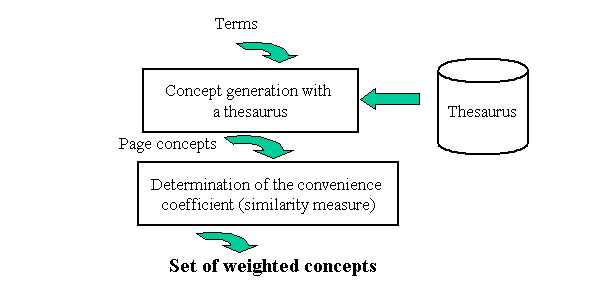
Figure 2. Concept generating and weighting
Then, figure 3 shows an extract of the XML file containing candidate concepts
(the DTD is presented in appendix 1).

Figure 3. Extract of a generated index