Searching for information on the Internet means accessing multiple,
heterogeneous and distributed information sources. Moreover, provided data
are highly changeable: documents of already existing sources may be updated,
added or deleted; new information sources may appear or some others may
disappear (definitively or not). In addition, the network capacity and
quality is a parameter that cannot entirely neglected. In this context,
the question is: how to search relevant information on the web more efficiently?
Many search engines help us in this difficult task. A lot of them use centralized
database and simple keywords to index and to access the information. With
such systems, the recall is often rather convenient. Conversely, the precision
is weak. Some works in the multi-agent community (Yuwono and Lee, 1996;
Ashish and Knoblock, 1997; Cazalens et al., 2000) show that an intelligent
agent supported by the web site may greatly improve the retrieval process.
In this context, this agent knows its pages content and is able to answer
or not to queries. Namely, web sites become "intelligent" and are able
to perform a knowledge-based indexation process on web pages. The work
presented in this paper is related to this framework i.e. how, a web site
can know its web page content and how ontologies can be used for information
retrieval purpose? Our project, called Thoth
(![]() ), plans
to respond as far as possible to these questions.
), plans
to respond as far as possible to these questions.
Keywords, which are used to index a site in usual approach, are natural language terms, which are basically ambigous. Working at the word level is not enough to disambiguate a query (Gonzalo et al., 1998) or to index a document (Luke et al., 1996; Fensel et al., 1998). To improve the information retrieval process on the web, we may work at the conceptual level. To this end, ontologies are often used. They are concept hierarchies, which provide the common vocabulary of a specific domain. For instance, a hierarchy as Yahoo! could be considered as a simple ontology (Labrou et al., 1999). In information retrieval processes, these ontologies are used in natural language context (web page are written in natural language). For this reason, an ontology concept is represented by a label which is often a term. These labels are the bridge between words in a page and associated ontology concepts. Therefore, at a label may correspond a single meaning. However, in natural language a term could have several meanings and a meaning could be represented by several terms. Therefore, a linguistic ontology can help to this disambiguation problem. In addition, extracting precise indexes from pages, which could represent the web page content, can improve the retrieval process. Indeed, web pages are written in natural language and included concepts can appear on different forms (synonyms for example). Natural language techniques, as terminological extraction and measuring of word similarities, can greatly help to collect all forms and to determine the associated concepts.
Inputs of this ontology based indexation process are (1) typical ontologies concerning the knowledge to highlight and (2) an HTML page set of a Web site. Briefly, an ontology is a set of concepts which are connected with relations. Our ontologies are enriched using a thesaurus to associate to each concept label the set of its possible synonyms. Ontologies are used to index the site (figure 1), that is to say we plan to associate, with each concept of the ontology, pages were they could be founded. We can call this process the ontology indexation of web pages. Namely, we first extract indexes that point out the site content from the HTML pages using natural language based techniques. An index of a web page is a term (a set of words), which can be a significant concept of this page. Second, we try to define concepts they could represent. Then, we match them with concepts of selected ontologies and a set of measures is computed to evaluate this process. Finally, either the process is ended (measures are convenient for the user) or another indexation process is started with a new ontology (if indexation results does not suit him/her).
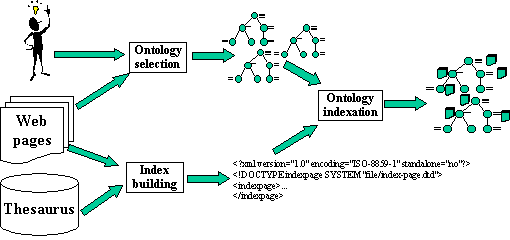
To detail this process, we also present: